繁體中文全文搜尋引擎實戰筆記(一):選型與架構設計
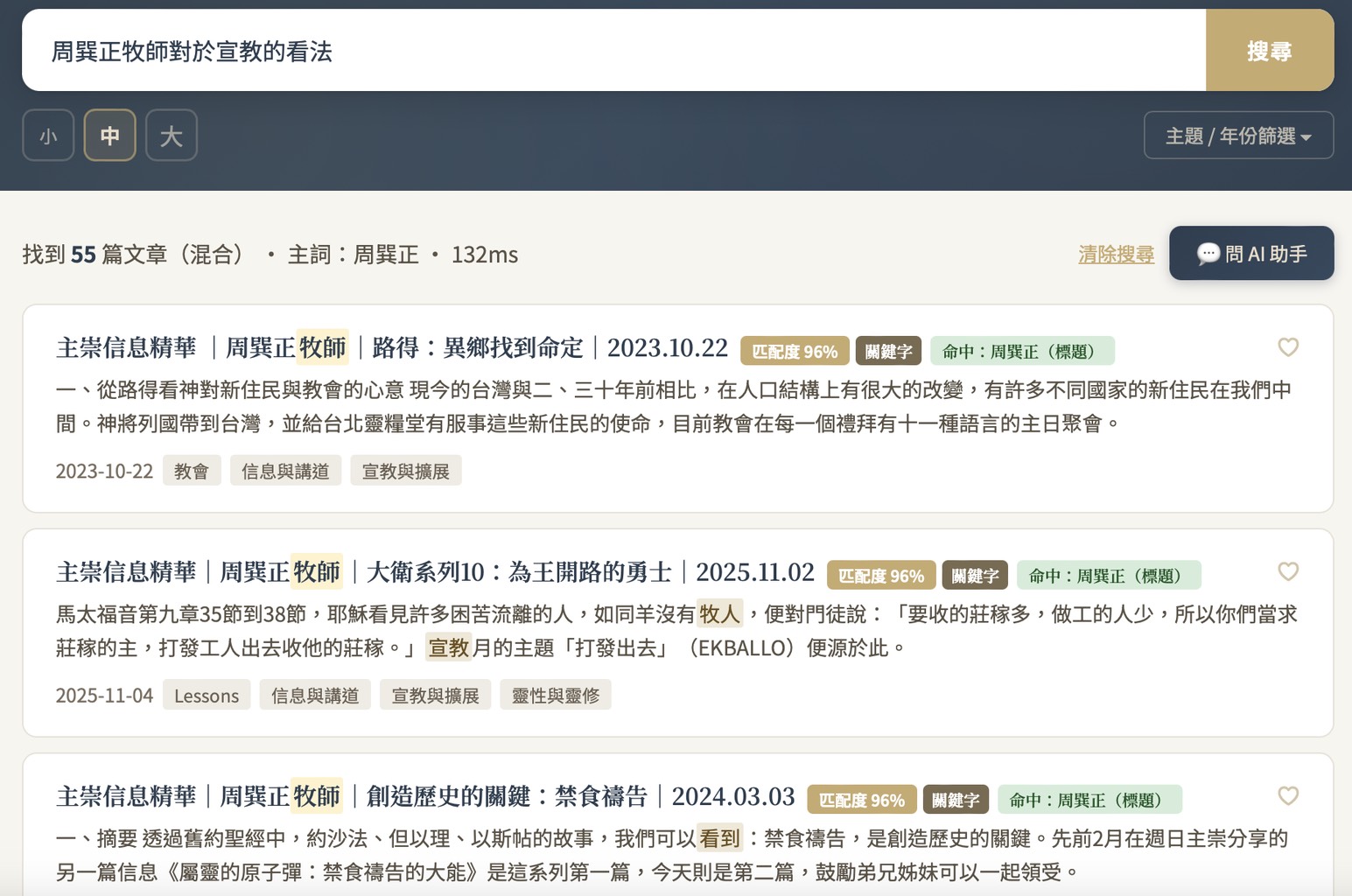
繁體中文全文搜尋引擎實戰筆記(一):選型與架構設計
這是三篇系列文章的第一篇。我用 Meilisearch + BGE-M3 在 Oracle Cloud 免費方案上,為一個 1800+ 篇繁體中文文章的知識庫建了一套搜尋系統。過程中踩了一輪中文分詞的坑,研究了市面上幾乎所有選項,最後疊加了四種互補手段才解決問題。這篇記錄選型過程和架構設計的決策脈絡。
起點:為什麼要自己建搜尋
我手上有一批教會歷年累積的文章——講道記錄、事工報導、人物見證,總共 1800 多篇。需要一套能讓同工透過網路搜尋、收藏、下載文章的方案。
一開始最直覺的做法是用 Google NotebookLM,但 1800 篇的量遠超過它的上傳限制,分資料夾或合併檔案雖然可用,但有其缺點,會失去全局搜尋能力,所以想了一輪後決定自建 XD
部署環境秉持站在巨人肩膀上的精神 XD ,完全使用 Oracle Cloud Free Tier(ARM64, 4 OCPU, 24GB RAM) 的方案。
繁體中文搜尋預處理工具-trad-zh-search-開源
假如有人想試試我的方案,我已經將它打包可以單獨搭配的套件,有興趣的人可以試試:
參考文章: 繁體中文搜尋預處理工具-trad-zh-search-開源
GitHub: notoriouslab/trad-zh-search
從 RAG 對話退到純搜尋
最早想做完整的 RAG 對話系統,選了 Open WebUI + Ollama(BGE-M3 embedding + Qwen3 8B 生成)。但很快撞牆:
- Oracle CPU-only 跑不動 LLM — Qwen3 8B 只有 3-8 tokens/sec,換過好幾個模型都太慢
- 使用量不確定 — 可以接 API 做生成,但不想一開始就綁付費方案
- 需求多元 — 宗教類的文章使用方式很多元,可能從查詢歷史文獻到特定人名做了什麼事,或是神學探討都已可能,與其需求複雜化,不如先從最基本的可以找到文章開始。
所以退一步:先做好「搜尋」這件事。 最後選了 Meilisearch 搭配 BGE-M3 做 hybrid search。Embedding 不需要 LLM 那麼多資源,CPU 跑得動。
結果人算不如天算 —— 就在繁體中文搜尋上踩了一大輪坑 XD
CJK 分詞:所有中文搜尋的痛
症狀
搜尋「生命河基金會」,預期回傳 1 篇精確匹配,實際回傳 175 篇。
原因:Meilisearch 內建的中文分詞引擎是 Rust 版 jieba(charabia),用簡體中文語料訓練,它把「生命河基金會」拆成了:
生命 / 河 / 基金 / 會於是所有包含「生命」或「會」的文章都被撈出來。
Meilisearch 本身的語法也有限制
| 語法 | 支援 |
|---|---|
"精確詞組" 雙引號 | 有 |
word1 word2 多詞(預設 OR) | 有 |
-排除詞 | 無 |
AND / OR 布林運算 | 無 |
* 萬用符號 | 無 |
| 正則表達式 | 無 |
Meilisearch 的定位是「打字即搜」的前端體驗(類似 Algolia),並不是全功能搜尋引擎。
Dictionary API——止痛藥
Meilisearch 提供 settings/dictionary API 可以加入自訂詞條。但實測發現只適合補幾百個專有名詞,大量灌入不切實際,專有名詞(人名、機構名)根本窮舉不完。
結論:Dictionary API 是止痛藥,不是治本方案。
Typesense:比 Meilisearch 更差(繁體中文環境)
網路上另外推薦的是 Typesense,但看了 Github 上的 Issue 後發現,它的中文支援能力可能比 Meilisearch 更差(對了,真的不要太相信 AI 給的推薦,一定要自己上 Github or Reddit 上看使用者的經驗或 Issue,會少走錯路,我一開始就是太相信 AI …)
| 項目 | Typesense | Meilisearch |
|---|---|---|
| 分詞引擎 | ICU 字典(基本逐字切) | Rust jieba(至少懂詞組) |
| 自訂字典 | 不支援(要重編譯 ICU) | 有 API |
| CJK Issue | #52,2019 年開到現在未解 | — |
Typesense創辦人坦承:「Since I don’t know Chinese, I don’t have much insights.」
**Reddit/GitHub 共識:Typesense 和 Meilisearch 的 CJK 支援都是「meh」XD **
搜尋引擎全景比較
| 工具 | 繁中分詞 | 自訂字典 | 布林語法 | 向量搜尋 | 部署難度 | RAM |
|---|---|---|---|---|---|---|
| Meilisearch | jieba(中等) | 有 API | 無 | 有(hybrid) | 低 | 低 |
| Typesense | ICU(差) | 不支援 | 無 | 有(hybrid) | 低 | 低 |
| Elasticsearch + IK | IK Analyzer(好) | 完整 | 完整 | 需 plugin | 高 | 高(8GB+) |
| OpenSearch | 同 ES 生態 | 同上 | 完整 | 有 neural search | 高 | 高 |
| Manticore Search | CJK ngram | 有 | 有 | 無 | 中 | 中 |
| SQLite FTS5 + jieba | 可自訂 tokenizer | 完整 | AND/OR/NOT/NEAR | 無 | 零 | 極低 |
| Tantivy(Rust) | 完全可自訂 | 完整 | 完整 | 需自建 | 高 | 低 |
選型小結:
- 要最好的繁中 keyword search → Elasticsearch + IK Analyzer(但很重)
- 要輕量 + 語意搜尋 → Meilisearch + embedding model
- 要零部署 → SQLite FTS5
- 要完全自訂 → Tantivy(需要 Rust 經驗)
所以我選了 Meilisearch,因為它輕量、有 hybrid search,而且 CPU 友善,分詞問題用其他方式繞過。
中文分詞工具深度比較
jieba 家族
| jieba(原版) | jieba-tw(APCLab) | jieba-php(fukuball) | |
|---|---|---|---|
| 技術原理 | DAG + HMM 統計模型 | 同 jieba,替換繁體詞庫 | Python 版移植 |
| 詞庫大小 | ~57 萬(簡體為主) | ~30 萬(繁體) | 含繁體字典 |
| 繁中支援 | 弱 | 好 | 好(big 模式) |
jieba 有三種模式:精確模式(最準)、全模式(列出所有可能組合)、搜尋引擎模式(在精確模式基礎上再拆分長詞,提高召回率)。
jieba-php 作者自己在 README 寫:「中文斷詞目前使用 LLM 大語言模型會得到更好的斷詞結果。」
jieba vs CKIP 的本質差異
| jieba 家族 | CKIP Transformers(中研院) | |
|---|---|---|
| 技術 | DAG + HMM 統計模型 | Transformer(BERT) |
| 繁中 F1 | 85-90%(推估) | 97.6%(官方數據,特定 benchmark) |
| NER(命名實體辨識) | 無 | 有(人名/地名/組織) |
| 遇到新詞 | 需手動加字典 | 模型自己判斷 |
| 速度 | 極快(毫秒級) | 較慢(CPU 數百毫秒/句) |
結論:jieba 對繁中的支援在 70-85 分的天花板,要突破就得試試 Transformer(CKIP)。
CKIP 家族全貌
CKIP 是中研院開發的繁體中文 NLP 工具系列:
ckipnlp ← 最上層:統一介面 pipeline
├── ckip-transformers ← 後端 A:Transformer 模型(BERT/ALBERT)
├── CkipTagger ← 後端 B:TensorFlow 神經網路
└── CkipClassic ← 後端 C:傳統統計方法搜尋引擎場景直接用 ckip-transformers 就夠了,模型有三種大小:ALBERT Tiny(4M)、BERT Tiny(12M)、BERT Base(102M)。我本來選 BERT Base,也跑了一堆文章,但後來覺得他速度實在有點慢,所以又冇起來測試了一輪,結果發現 …
CKIP 模型分詞比較報告
| 句子 | albert-tiny | bert-tiny | bert-base | 誰最好 |
|---|---|---|---|---|
| 改革宗教會 | 改革 | 宗教會 | 改革 | 宗教 | 會 | 改革 | 宗教 | 會 | 都不好,需詞典 |
| 護教學 | 護 | 教學 | 護 | 教學 | 護教學 ✅ | bert-base |
| 因信稱義 | 因 | 信 | 稱義 | 因 | 信 | 稱義 | 因 | 信 | 稱 | 義 | albert/bert-tiny |
| 神不理我 | 神 | 不 | 理 | 我 ✅ | 神不理 | 我 ❌ | 神 | 不 | 理 | 我 ✅ | albert/bert-base |
| 睡著 | 睡 | 著 | 睡著 ✅ | 睡著 ✅ | bert-tiny/base |
| 神愛我 | 神愛 | 我 ❌ | 神 | 愛 | 我 ✅ | 神 | 愛 | 我 ✅ | bert-tiny/base |
| 信主了 | 信主 | 了 ✅ | 信主 | 了 ✅ | 信 | 主 | 了 ❌ | albert/bert-tiny |
| 佈道大會 | 佈道大會 | 佈道 | 大會 | 佈道 | 大會 | 看語境都行 |
| YouTube | You | Tube ❌ | You | Tube ❌ | YouTube ✅ | bert-base |
CKIP 模型分詞速度比較
| 模型 | 23 句耗時 | 相對速度 |
|---|---|---|
| albert-tiny | 0.26s | 1x(最快) |
| bert-tiny | 0.50s | 1.9x |
| bert-base | 3.46s | 13.3x(最慢) |
沒有哪個模型穩定最好。 三者各有勝負:
- bert-base:贏在「護教學」「YouTube」,但輸在「因信稱義」「信主」
- albert-tiny:贏在「因信稱義」「信主」,但輸在「神愛」黏一起、YouTube 切碎
- bert-tiny:最均衡,但也有「神不理」黏一起的問題
15/23 句三者結果完全一樣——生活化口語切得都很好(小組、聚會、奉獻、拜拜…)。
差異集中在神學專有名詞和邊界模糊的詞,而這些正好是自訂詞典能修的,跑完測試後我又改用了 albert-tiny :P
關鍵心得:NLP 最佳分詞 ≠ 搜尋最佳分詞
這是整個研究中最重要的一個發現。
CKIP 的 97.6% F1 是 NLP 語法正確度的指標,但搜尋引擎更重視的是 recall(不漏結果),而非語法精準。
舉個例子:CKIP 把「生命河基金會」切成一個 token,語法上完美。但使用者搜「生命河」時,因為 index 裡只有完整的「生命河基金會」token,反而匹配不到。
jieba 的搜尋引擎模式會切成「生命河 / 基金會 / 生命 / 基金」,語法不精確,但召回率更高。
所以 CKIP 的最大價值在 NER(辨識人名、組織名),不在搜尋分詞本身。
Embedding 模型選型
BGE-M3——最終選擇
BGE-M3 專為多語言設計,繁體中文原生支援:568M 參數,1024 維向量,支援 dense + sparse + ColBERT 三模式檢索,max tokens 8192。
繁中 Embedding 實測排名
台灣開發者 ihower 用 DRCD(台灣閱讀理解語料庫,1,000 段落 + 3,493 題)做的評測,是目前最有參考價值的繁中實測數據:
| 模型 | 類型 | Hit Rate (top-5) | 備註 |
|---|---|---|---|
| Voyage Multilingual-2 | 付費 API | 97%(第一) | 最貴 |
| multilingual-e5-large | 開源 | 95% | 512 token 限制 |
| BGE-M3 | 開源 | 前段班 | 我在用的 |
| OpenAI text-embedding-3-small | 付費 API | 競爭力強 | 性價比高 |
| Google text-embedding-004 | 付費 API | 極差 | 繁中支援炸裂 |
ihower 的關鍵結論:「有沒有支援中文差很多」——沒有中文訓練資料的模型直接爆炸。
為什麼不用 Jina v3
| BGE-M3 | Jina v3 | |
|---|---|---|
| 參數量 | 568M | 570M |
| 推理延遲 | 29ms | 85ms(慢 3 倍) |
| 授權 | MIT | CC BY-NC 4.0 |
Jina v3 有獨特的 Task LoRA 適配器,但繁中缺乏專項評測、延遲多 3 倍、CC BY-NC 授權有商業限制,純搜尋場景沒有明顯優勢,所以沒有選它。
小模型可以省資源嗎?
multilingual-e5-small(118M 參數)看起來很誘人,但 MIRACL 中文 benchmark 的 nDCG@10 只有 45.9,BGE-M3 是 63.9——差 18 分,而且 mE5 全系列 max tokens 只有 512,長文章後半段直接被截斷。
BGE-M3 仍然是目前開源繁中檢索的最佳選擇。
另外值得關注 Qwen3-Embedding-0.6B,在 MTEB/CMTEB 全面超越 BGE-M3,但尚未有繁中專項評測,而我已經開用了BGE-M3 匯入一堆文章,也不想再換核心重跑了。
2026-03-28 更新:Qwen3-Embedding-0.6B vs BGE-M3 繁中實測
終於實測了。結論:BGE-M3 在繁中檢索場景依然完勝 Qwen3-Embedding-0.6B。
測試環境:Oracle ARM64 Ampere A1(4 core, 24GB RAM),ONNX Runtime CPU 推理。
速度比較:
| 指標 | BGE-M3 ONNX INT8 | Qwen3-Embedding-0.6B ONNX uint8 | Qwen3 ONNX FP32 |
|---|---|---|---|
| 短 query(搜尋) | ~30ms | ~140ms | ~350-430ms |
| 長文本(1000 字) | ~數秒 | ~3.6s | ~3.6s |
| 架構 | Encoder(雙向注意力) | Decoder(因果注意力) | Decoder |
Qwen3 的 decoder 架構先天比 encoder 慢——同樣 0.6B 參數,推理速度差 5-15 倍。
品質比較(致命差距在區分度):
| Query: 「產假」 | BGE-M3 | Qwen3 uint8 | Qwen3 FP32 |
|---|---|---|---|
| 勞基法條文:產假八星期(相關) | 0.609 | 0.995 | 0.463 |
| 內部規章:產假規定(相關) | 0.601 | 0.994 | 0.436 |
| 資產管理辦法(不相關) | 0.371 | 0.992 | 0.382 |
| 相關 vs 不相關 gap | ~0.2 | ~0.002 | ~0.06 |
- Qwen3 uint8:所有文件 cosine similarity 都在 0.991-0.995,相關和不相關幾乎分不開。uint8 量化把 embedding 空間壓扁了。
- Qwen3 FP32:區分度只有 0.06(相關 0.44 vs 不相關 0.38),BGE-M3 是 0.2——差 3 倍以上。
可能原因:Qwen3-Embedding 使用 decoder 架構,mean pooling 可能不是最佳 pooling 策略(decoder 通常用 last token pooling)。但 ONNX 導出版使用 mean pooling,且 uint8 版的 sentence_embedding_quantized 直接輸出也有同樣問題。
結論:BGE-M3 在 ARM64 CPU 上是繁中 embedding 的最佳選擇。 速度快、區分度好、ONNX INT8 量化後品質保持完好。Qwen3-Embedding 可能在 GPU 推理 + FP16/BF16 下表現不同,但在 CPU + 量化場景完全不行。
決策框架與最終架構
場景選型指南
- 幾百到幾千篇繁中文章 + 輕量部署 → Meilisearch hybrid search + bigram 雙欄位
- 需要精確 keyword search + 布林語法 → Elasticsearch + IK Analyzer(最成熟但最重)
- 想要最佳分詞品質且不怕工程量 → CKIP Transformers 前置分詞 + Meilisearch
- 預算充足 → Algolia / Azure Cognitive Search
架構哲學
這次的經驗讓我學到一個原則:先解決「找到」,再解決「理解」。
搜尋和 AI 對話是兩個獨立的需求,搜尋是基礎設施,做好了誰都能用;AI 對話是上層應用,每個人需求不同,Open WebUI 不是不好,但它把搜尋和 AI 綁在一起 —— 當 LLM 跑不動時,搜尋也跟著廢了。
最終架構
前端(靜態 HTML)
↓ /multi-search API
Meilisearch
├── keyword search(jieba 原文 + bigram 欄位 + CKIP 欄位)
├── vector search(BGE-M3 ONNX INT8 embedding)
└── synonyms(專業術語同義詞擴展)
↓
三路合併,最高分排序
↓
Cross-encoder Reranking(BGE-reranker-v2-m3 ONNX INT8)
↓
Entity-Aware Scoring(主詞硬篩 + coverage + 別名展開)部署在 Oracle Cloud Free Tier 上,零成本,但花了很多時間測試。
優化路線圖
| 優先順序 | 項目 | 觸發條件 |
|---|---|---|
| 1 | Bigram + CKIP 雙欄位 | 基礎必做 |
| 2 | Cross-encoder Reranking | 文章量 2000+,前幾名不準 |
| 3 | Entity-Aware Scoring | 人名查詢結果混雜 |
| 4 | Paragraph Chunking + RRF | 需要 RAG 問答或細節搜尋 |
原則:先用 80 分方案上線,有明確痛點再追 90 分。
參考資源
- Meilisearch 官方文件
- charabia - Meilisearch 的 Rust 分詞引擎
- Typesense GitHub Issue #52 - CJK Support
- fxsjy/jieba - 原版 Python jieba
- APCLab/jieba-tw - 繁體中文 jieba
- CKIP Transformers - 中研院繁中 NLP
- BGE-M3 (HuggingFace)
- ihower 的繁體中文 Embedding 模型評測
- MIRACL Benchmark - 多語言檢索評測
下一篇:(二)建置實戰與測試——四種解法的實作細節、ONNX Runtime 42 倍加速、以及從 516 篇到 7600+ 篇的四輪品質演進數據。